عمرك فكّرت ليه شركة كبيرة زي Google كل أنظمتها شغالة بثبات رهيب حتى وهي بتخدم ملايين المستخدمين كل يوم؟ ده مش صدفة ولا بسبب الهندسة والأدوات لوحدهم… السر الحقيقي هو إنهم عايشين بمبدأ بسيط اسمه Practice Excellence… يعني كل خطوة مهما كانت صغيرة تتعمل صح من أول مرة.
فيه ظاهرة جديدة اسمها vibe coding، يعني مثلاً تفتح Cursor وتطلب منه يكتب لك كود وانت قاعد بتتفرج وبتشرب قهوتك… الحقيقة إن النتيجة دي في الغالب بتبقى سيئة جداً، مافيش حاجه من غير عرق وصبر. الـ Cursor ده مش ساحر، لكن تقدر تعتبره طفل عبقري... محتاج حد يفهمه ويوجّهه ويعرف يطلّع منه نتايج حقيقية… ده اللي هاتكلم عنه في المقالة دي.
في أي system كبير بيبقى عندك المعادلة الصعبة دي: إزاي تعطي المستخدم أداء عالي وفي نفس الوقت ما تصرفش كتير على resources مش محتاجها؟ الحل بيبدأ من إنك تراقب الـ system صح. جوجل في كتاب Site Reliability Engineering (SRE) اقترحت ٤ مؤشرات أساسية وسَمّتهم: The Golden Signals. الإشارات دي بقت الأساس لأي observability strategy ناجحة.
لما بتشغل تطبيق على Kubernetes، الـscheduler هو اللي بياخد قرار يحدد فيه الـpod هتروح على أنهي node. لكن أحياناً بتحتاج تتحكم في القرار ده بنفسك عشان تضمن إن الـpods اللي محتاجة موارد معينة (زي GPUs أو SSDs) تروح على الـnodes اللي فيها الموارد دي بس. فيه أكتر من طريقة للتحكم ده، كل واحدة ليها استخدامها ودرجة تعقيدها.
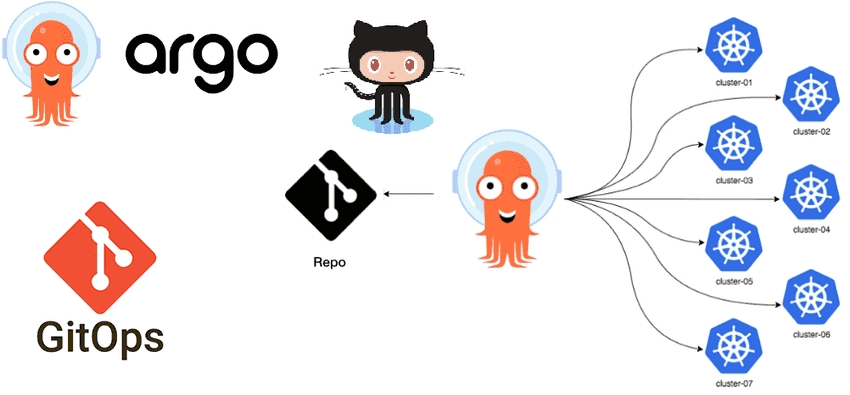
في عالم التكنولوجيا السريع، الشركات بقت محتاجة تنشر تطبيقاتها بسرعة وكفاءة من غير أي أخطاء. الطريقة التقليدية، اللي بتعتمد على تدخل الإنسان في كل خطوة، بقت بطيئة وكلها مشاكل. هنا بيظهر دور الـ DevOps، اللي بيهدف لربط التطوير والتشغيل عشان العمليات دي تبقى سلسة وأوتوماتيكية. لكن حتى مع أدوات الـ DevOps، لسه فيه تحديات كبيرة، خاصة لما بنتعامل مع حاويات (Containers) ومنصات ضخمة زي Kubernetes. هنا بيجي دور ArgoCD. إيه هو ArgoCD؟ في المقال ده هانتكلم عن ArgoCD، مفاهيمه ومكوناته وإزاي ممكن تستفيد بيه.